- Formule de Cauchy Binet
- Trois petites fables en économie
- Mecanique Bohmienne et vecteur potentiel
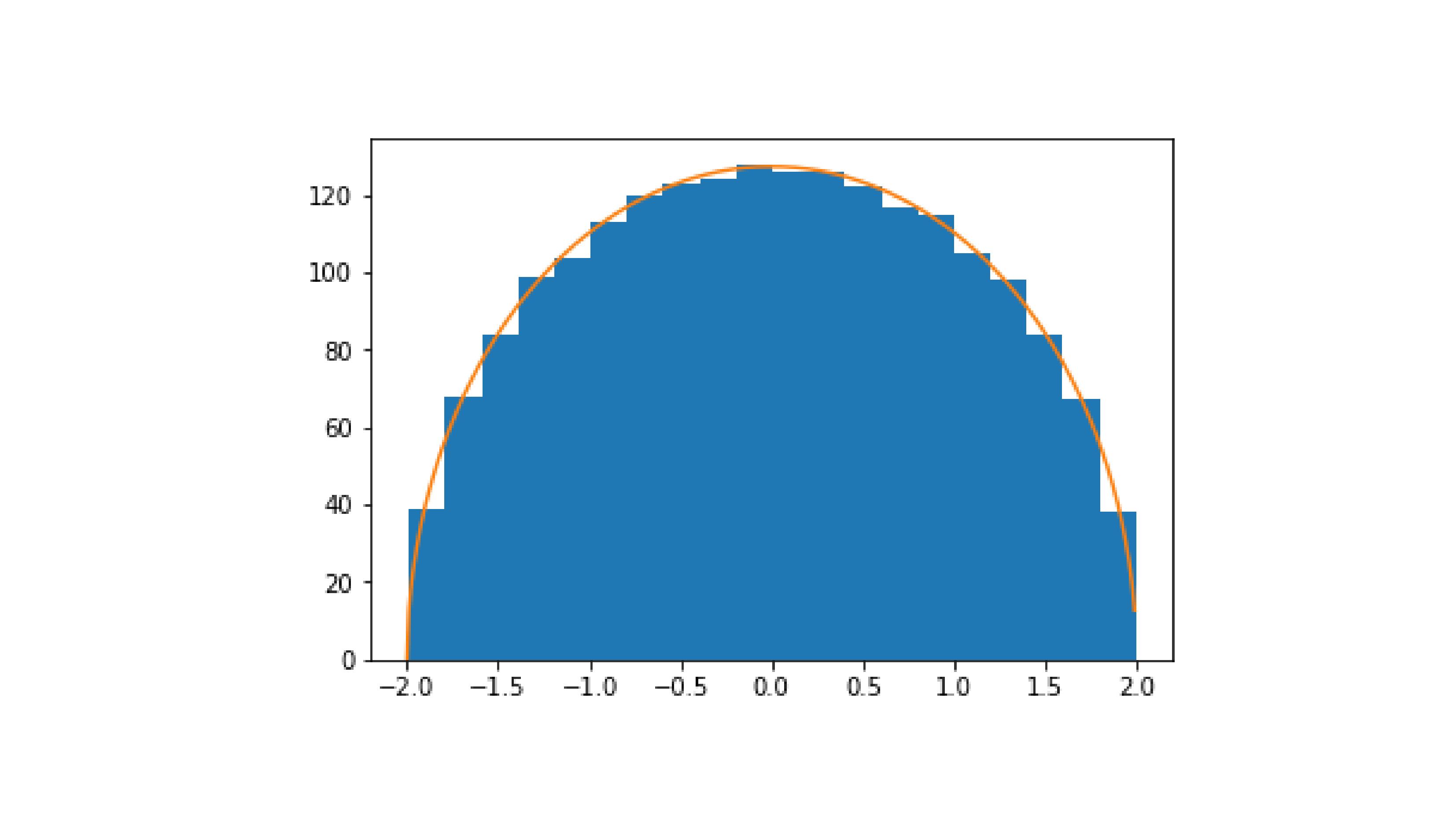
- Un peu de proba en arithmétique
- Dessiner la relativité générale ?
- Un peu de cryptographie partagée
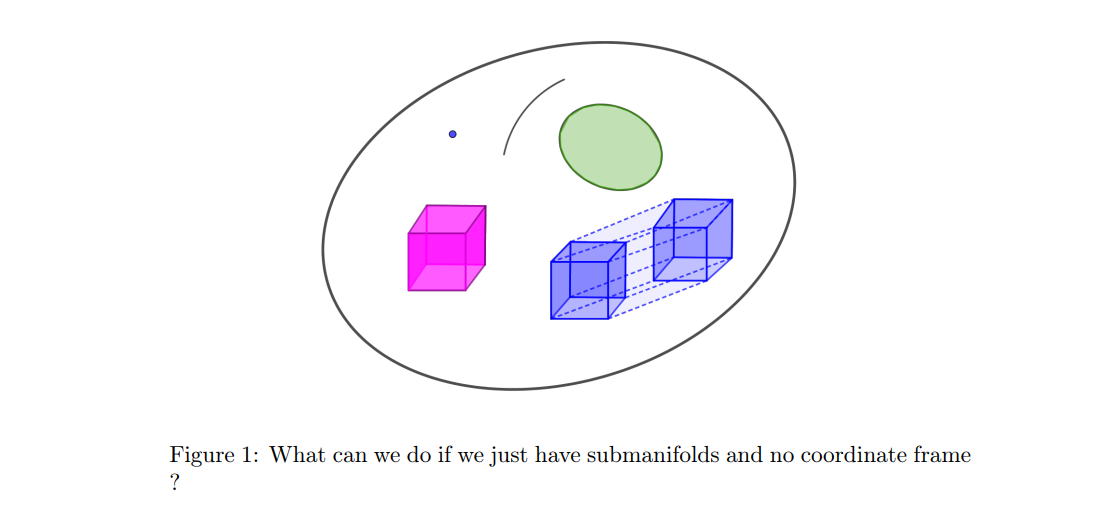
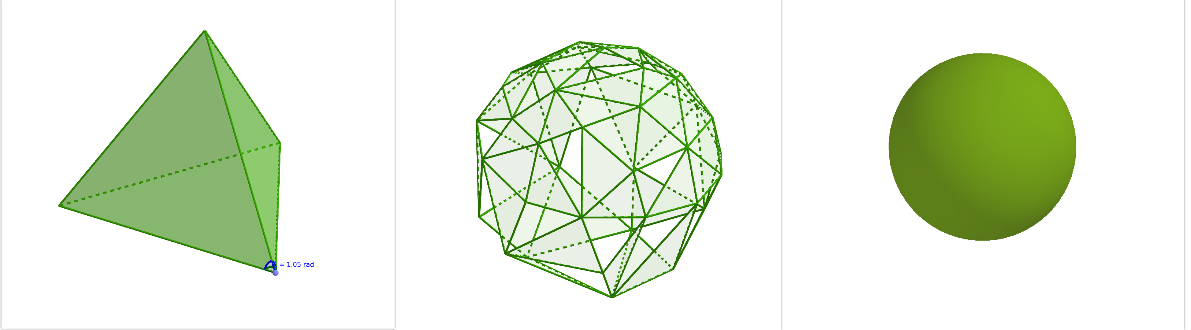
- Un version simplifié du théorème de Gauss Bonnet
- Formes différentielles et équations de Maxwell
- Le problème du collectionneur et la loi de Poisson
- Un peu de théorie des jeux
- Formule de la résolvante et théorie des perturbations
- L'urne de Polya